

- cross-posted to:
- [email protected]
- cross-posted to:
- [email protected]
cross-posted from: https://lemmy.zip/post/24335357
You must log in or register to comment.
Isn’t it all unicode at the end of the day, so it supports anything unicode supports? Or am I off base?
Ssh! 🫢 You’ll ruin the joke!
Okay but how does starting a secure shell help?
Are you serious? I just explained that to you two seconds ago
Well for one, it encrypts all communications so that people can’t snoop on what you’re doing.
😨
Yes, but the language/compiler defines which characters are allowed in variable names.
I thought the most mode sane and modern language use the unicode block identification to determine something can be used in valid identifier or not. Like all the ‘numeric’ unicode characters can’t be at the beginning of identifier similar to how it can’t have ‘3var’.
So once your programming language supports unicode, it automatically will support any unicode language that has those particular blocks.
Sanity is subjective here. There are reasons to disallow non-ASCII characters, for example to prevent identical-looking characters from causing sneaky bugs in the code, like this but unintentional: https://en.wikipedia.org/wiki/IDN_homograph_attack (and yes, don’t you worry, this absolutely can happen unintentionally).
OCaml’s old m17n compiler plugin solved this by requiring you pick one block per ‘word’ & you can only switch to another block if separated by an underscore. As such you can do
print_แมวbut you couldn’t dopℝint_c∀t. This is a totally reasonable solution.That’s pretty cool
I can’t imagine how something like homograph attacks can happen accidentally. If someone does this in code, they probably intended to troll other contributors.
Multilingual users have multiple keyboard layouts, usually switching with Alt+Shift or similar key combo. If you’re multitasking you might not realize you’re on the wrong keyboard layout. So say you’re chatting with someone in Russian, then you alt+tab to your source code and you spot a typo - you wrote
my_var_xopyinstead ofmy_var_copy. You delete the x and type in c. You forget this happened and you never realized the keyboard layout was wrong.That c that you typed is now actually с, Cyrillic Es.
What do you say, is that realistic enough?
I use multilingual keyboard layouts, so I know that at least on Windows, the selected layout is specific to each window. If I chat with someone in one language, then switch to my IDE, it will not keep the layout I used in the chat window.
But I also have accidently hit the combination to change layouts while doing something, so it can happen. I’m just surprised that Cyrillic с is on the same key as C, instead of S.
I believe there’s a setting for whether it’s global or per-window. Personally I prefer global, because I can’t keep track of more than one state and I absolutely hate the experience of typing something and getting a different language than you expect.
Sorry, I forgot about this. I meant to say any sane modern language that allows unicode should use the block specifications (for e.g. to determine the alphabets, numeric, symbols, alphanumeric unicodes, etc) for similar rules with ASCII. So that they don’t have to individually support each language.
Oh, that I agree with. But then there’s the mess of Unicode updates, and if you’re using an old version of the compiler that was built with an old version of Unicode, it might not recognize every character you use…
Yes, but it still is about language, not game engine.
Albeit technically, the statement is correct, since it is more specific.
Yeah, but this particular language is a feature of the game engine. It’s its own thing called GDScript.
Oh, I didn’t know that, neat. Then there’s no space for nit-picking
Godot is neat. There is C# support as well if you find that easier, but coming from Unreal, it’s night and day. I know Unreal has so much more features, but for a hobbyist like me, Godot is much better. It’s just this small executable, and you have everything you need to get creative.
I think they exclude some unicode characters from being use in identifiers. At least last I tried it wouldn’t allow me to use an emoji as a variable name.
Another guy just posted emojis in their code in the comments no idea if it actually works
That code was C++ or something like that. Not GDScript.
I tested this on Godot 4.2.1. You can write identifiers using a different writing system other than latin and you are allowed to have emojis in strings, but you aren’t allowed to use emojis in identifiers.

Ah I’m unfamiliar with most languages I just use python and random others for personal projects
Coding must be a nightmare if you’re choosing programming languages at random 😱
But you must also be learning quite a lot.
I’m not choosing at random lol that would be crazy but I mostly use python and have been teaching myself go and some rust
There’s probably a rule that requires variables to start with a letter or underscore. Emoji are nor marked as letters. Something like
_👍will probably work.
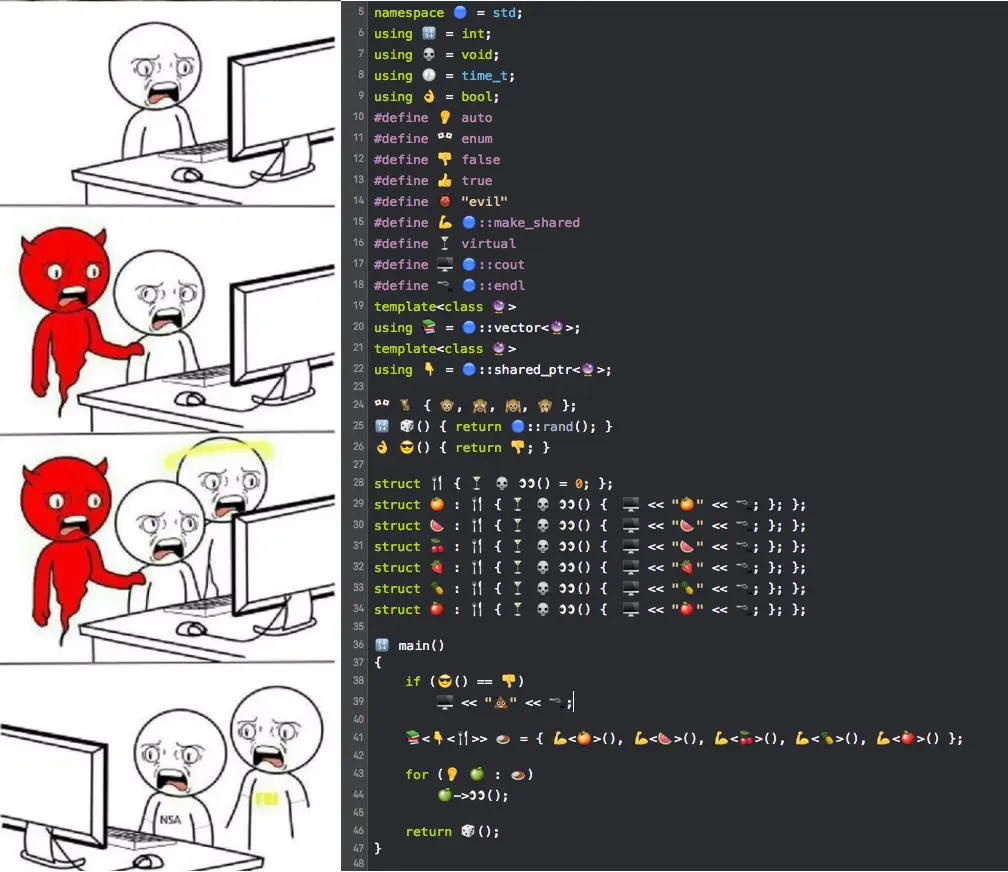
Thank you for this cursed knowledge.
May I introduce you to emojicode…
Am I blind? I can’t see where 👀 is defined.
Take a look at all the struct definition. It’s a pure virtual method of 🍴 with a bunch of overrides in the structs that inherit from 🍴.
Oh, right, using the same function name in multiple structs is what threw me off
A little LESS chaotically, you can use emojis to name objects in Blender now… Which, I dunno, could be kinda fun in the right doses.
This picture had me progressively laughing harder as it progressed though LOL.
Let’s hope Ea-nāṣir’s code is better than his copper.
I hear it’s prone to Rust.
Ea Nasir over here selling subpar code now
Security by
ObscurityAntiquityThanks, I hate it
Don’t you mean 𒁷𒀱𒀉?
Unironically awesome. You can debate if it hurts the ability to contribute to a project, but folks should be allowed to express themselves in the language they choose & not be forced into ASCII or English. Where I live, English & Romantic languages are not the norm & there are few programmers since English is seen as a perquisite which is a massive loss for accessibility.
The hotter take: languages like APL, BQN, & Uiua had it right building on symbols (like we did in math class) for abstract ideas & operations inside the language, where you can choose to name the variables whatever makes sense to you & your audience.
Yeah. Tbh, I always wondered why programming languages weren’t translated.
I know CS is all about english, but at least the default builtin functions of programming languages could get translated (as well as APIs that care about themselves).
Like, I can’t say I don’t like it this way (since I’m a native english speaker), but I still wonder what if you could translate code.
Variables could cause problems (more work with translation or hard to understand if not translated). But still - programming languages have no declentions and syntax is simpler so it shouldn’t even compare to “real” languages with regards to difficulty of implementation.
I’m German, and I would not want that. German grammar works differently in a way that makes programming a lot more awkward for some reason. Things like, “.forEach” would technically need three different spellings depending on the grammatical gender of the type of element that’s in the collection it’s called on. Of course you could just go with neuter and say it refers to the “items” in the collection, but that’s just one of lots of small pieces of awkwardness that get stacked on top of each other when you try to translate languages and APIs. I really appreciate how much more straightforward that works with English.
Programs aren’t written by a single team of developers that speak the same language. You’d be calling a library by a Hungarian with additions from an Indian in a framework developed by Germans based on original work by Mexicans.
If no-one were forcing all of them to use English by only allowing English keywords, they’d name their variables and functions in their local language and cause mayhem to readability.
[Edit:] Even with all keywords being forced to English, there’s often half-localized code.
I can’t find the source right now, but I strongly believe that Steve McConnell has a section in one of his books where he quotes a function commented in French and asks, “Can you tell the pitfall the author is warning you about? It’s something about a NullPointerException”. McConnell then advises against local languages even in comments
Excel functions are translated. This leads to being pretty much locked out of any support beyond documentation if your system language isn’t English.
Honestly it wouldn’t even be that hard to release full translated versions of existing programming languages. Like Python in Punjabi or Kotlin in Chinese or something (both of which already support unicode variable/class/function names). Just have a lookup table to redefine each keyword and standard library name to one in that language, it can literally just be an additional translation layer above the compiler/interpreter that converts the code to the original English version.
It’s honestly really surprising that non-English speakers have developed entirely new programming languages in their own language (unfortunately none of which are getting very widespread use even among speakers of that language), but the practice of simply translating a widely used and industry standard English programming language doesn’t seem to be much of a thing.
If I ever make my own programming language, I’m probably going to bake multi-language support into the compiler. Just supply it with a lookup table of translated terms and the code in that language.
Isn’t unicode support for programming not something new? I’ve seen a lot of code using Cyrillic or Chinese characters.
Inside of strings or comments or as an encoding is close to universal now, but for wide support for operators & variable names I would generally it isn’t. Some languages straight up do not support non ASCII like OCaml, others only support bicameral scripts like PureScript, but others like JavaScript can support Unicode for variable names but doesn’t support defining infix operators or uses Unicode for any existing operators. Raku is probably the most Unicode-friendly language, & some of the mathier ones like Agda as well.
now that’s job security
This is how we end up with snow crash.
Iltam sumra rashupti ilatimmoment 🗿Wtf I just said these words out loud and the furniture started floating o.o
https://www.soas.ac.uk/baplar/recordings/ammi-ditanas-hymn-istar-read-k-hecker
So i guess iltam = goddess and ilatim = gods?
litta = praise be (to), zumrā = sing of and rašubti = fearsome being?
deleted by creator
Bro thats fucking amazing 😂
Most languages are like this. Even C is like this.
Depends on the compiler, I’m pretty sure some versions of Borland shit themselves if you introduce an accent mark at the wrong time, much less support Unicode.
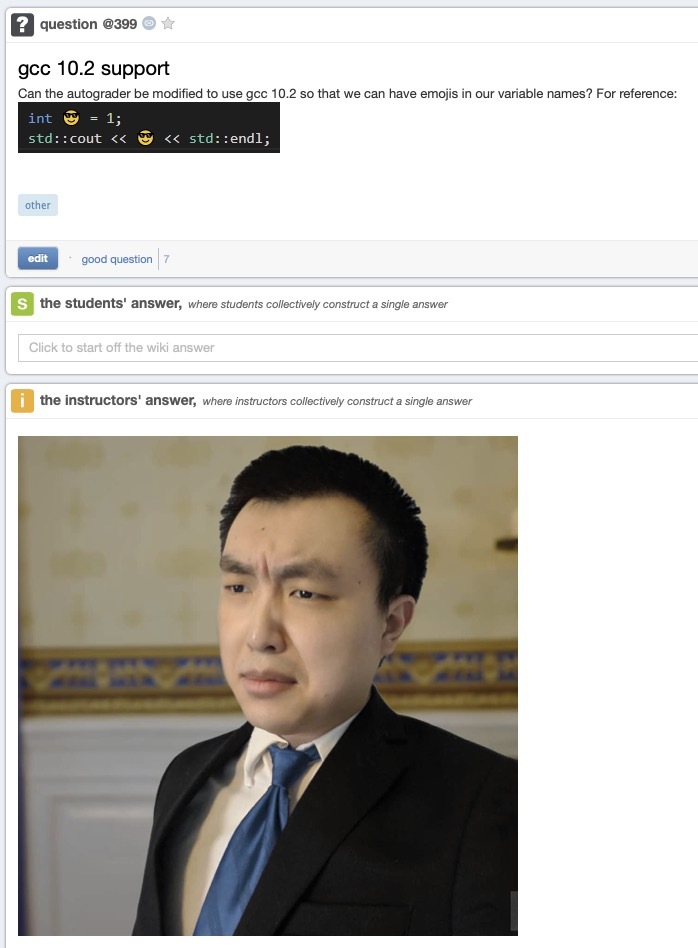
Amazing that someone would ask that on Piazza.
It really bugs me when people don’t comment their code at all. I have no idea what this is supposed to do.
Duh
I don’t know much about coding, but I know Cuneiform isn’t an alphabet.













{kind=link}