They’ve posted on Mastodon, that it is a (D)DoS: https://linuxrocks.online/@[email protected]/113995906036180301
Ephera
- 14 Posts
- 483 Comments
Joined 5 years ago
Cake day: May 31st, 2020
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.
Those regex crosswords ain’t gonna solve themselves…

 3·9 days ago
3·9 days agoThey’re not saying to create Linux-exclusive games. Just games that run on Linux without WINE/Proton.
 1·13 days ago
1·13 days agoFirst option for small codebases. Second option when you know your codebase will grow large enough to break things apart into multiple packages.
The thing is, you typically need dependencies for de-/serialization. You only want those dependencies in the parts of the codebase that actually do the de-/serializing. And your model will likely be included in pretty much everything in your codebase, so the de-/serializing code should not be in there.
Well, unless your programming language of choice supports feature flags with which the de-/serializing code + dependencies can be excluded from compilation, then you can think about putting it into the model package behind a feature flag.
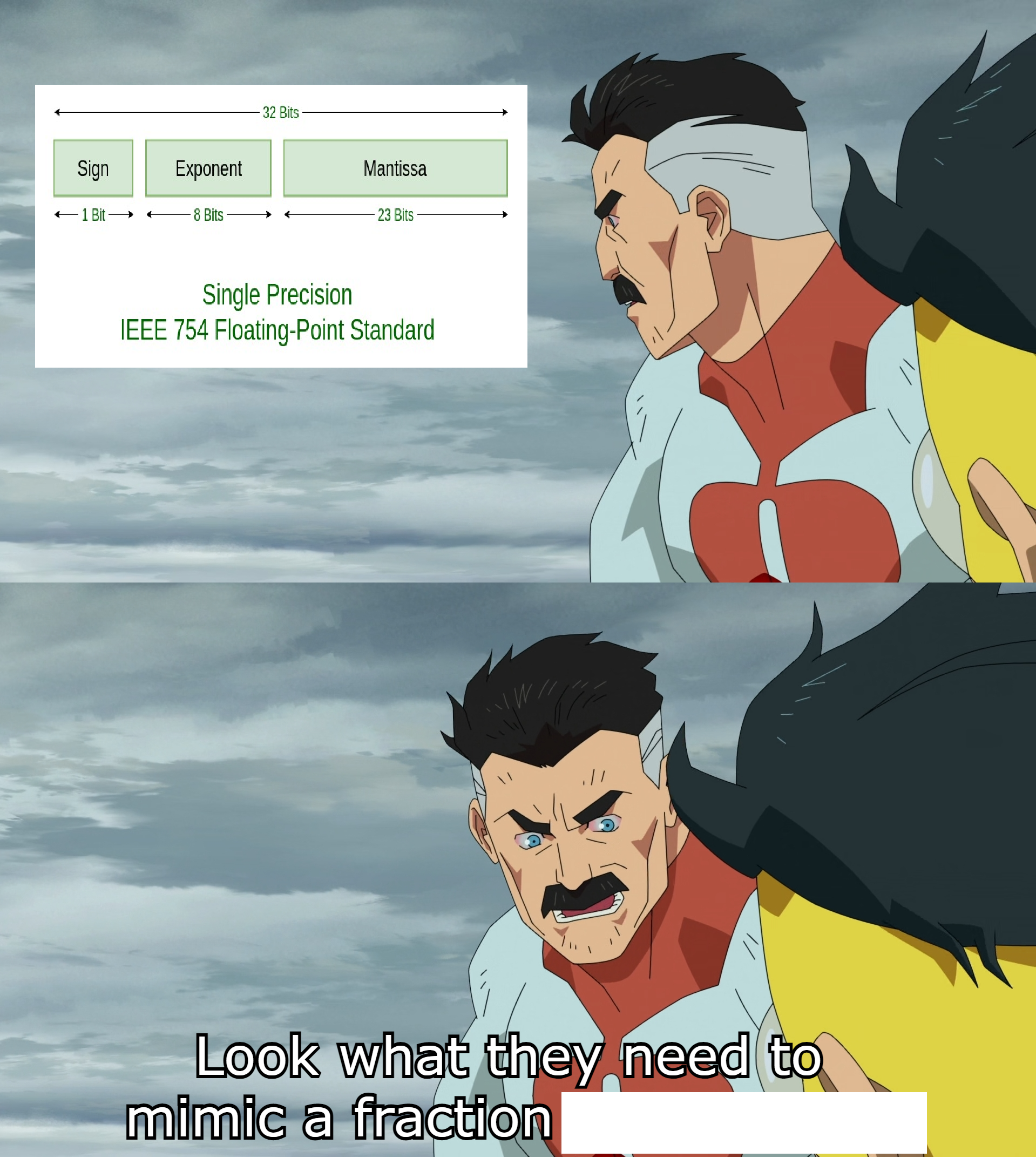
I still don’t get why the backslash is on keyboards to begin with. I don’t think I’ve ever seen anyone write a slash backward with a pen. And even if folks do, you could’ve had only one slash anyways. Like, people are going to understand what it means, whether it’s
/or\.I guess, it not being used for much else, does at least make it useful for escaping stuff and for Windows to use as path separator.
we would like to officially announce that this will be the [last] version labeled Alpha. We have already updated the versioning scheme (this version being 0.27.0) and we will progressively stop using the Alpha label altogether up to the next release, which will be Release 28.
Excellent. Whenever I told people about 0 A.D., I felt like I should add that it’s not actually an Alpha, especially with their webpage saying in various places basically “no, don’t look at us yet, we’re not ready yet”.
If they continue adding content, I do think that’s awesome, but what’s there is already plenty solid.
It’s only really Windows that doesn’t use LF these days. All the Unix-based ones (Linux, BSD, macOS, iOS, Android etc.) use LF…
I need something without understandable lyrics (unless I’ve listened to that song many times before) and something that pumps me up, but doesn’t cause headaches. So, 8-bit music and cheesy / ‘epic’ cinematic scores work well.
Well, unless it’s 4 o’clock in the morning. Then nothing beats classical music. I’m never as productive as I am at 4 AM, listening to Beethoven and friends.
 14·23 days ago
14·23 days agoAlternatively, the less proper tool: Record your screen, cropped to the SVG.
GIF, MP4 and such, they’re just a bunch of pixel grids. They don’t care where those pixels came from.
I’ve heard the reasoning before that reviewers typically only have access to a, well, pre-release version. A day-1-patch is pretty common now.
So, as reviewer, you have to decide whether the performance problems look like they might be fixed on release day, and therefore whether you want to incorporate them into your review/score or not.
I was kind of thinking that yesterday when looking at a Rust library. Rust is competent with line numbers, so you don’t really have an incentive for splitting files from that angle, but sometimes, folks just seem to keep adding to their files ad infinitum.
Well, specifically that library has a few files with more than 1k lines. And I hope this one’s the largest at 4k lines: https://docs.rs/git2/latest/src/git2/repo.rs.html
What also needs to be said, is that this library is actually maintained by the Rust language team. Really makes me want to open an issue to tell them that Rust has a pretty cool module system. 🙃
Apparently, a dev on the customer side estimated that he’d need two weeks to implement the whole project (which thankfully our customer representative also laughed at).
Man, I’m currently in a project which started out with 2 major goals. Pretty early on, we got told that one of the goals is practically impossible, so we decided to ignore that. And we realized the other goal needs to be simplified significantly to be achievable in the slightest, although we still weren’t sure, if it violates the laws of physics.
Now we’re a year into development, we’ve only figured out that it might be physically possible in certain situations. And yesterday, we talked to a guy with domain knowledge, who told us like ten different bigger challenges we’d still have to solve.
 8·28 days ago
8·28 days agoYeah, direct link: https://f-droid.org/en/packages/org.fossify.gallery/
I looked through F-Droid a while back and liked this one the best.
It also has to be said that mobile operating systems are terrible platforms for getting into programming. The gateway drug for programming is scripting and that’s pretty much impossible there, at least without doing it in some existing automation app, which isn’t going to be a transferable skill.
Even if you do have a PC to try to develop a full-fledged app, that’s an incredibly daunting endeavor. I could probably code out ten CLIs in a shorter time frame than one simple app.
Let’s see, the EDPS pointed out that the EU Commission using Microsoft 365 is illegal: https://www.edps.europa.eu/press-publications/press-news/press-releases/2024/european-commissions-use-microsoft-365-infringes-data-protection-law-eu-institutions-and-bodies_en
…and now we have a different EDPS: https://www.europarl.europa.eu/news/en/press-room/20250108IPR26254/meps-choose-bruno-gencarelli-as-top-candidate-for-eu-data-protection-watchdog
Somehow, I’m not filled with confidence. 🫠
Certainly some food for thought, but I feel like people saying indies will save us are saying that as consumers and a lot more selfishly. AAA is struggling to deliver interesting games and indies are killing it, so you play indie titles instead. Whether those indie titles are actually produced organically and whatnot is kind of secondary for that purpose. The mass layoffs in AAA are bad, but in the New York Times article, for example, they’re mainly seen as indicative of the business model faltering, which should naturally give more room for indies. But yeah, that these studios are still horrendously profitable kind of shows that this may not be true in the end.
 16·1 month ago
16·1 month agoAnd here I would argue that the Rust library is strictly better, specifically because it will come with an automated or precompiled build of the C library. Compiling C is such a pain.
I’m not expecting insane test coverage. What I’m looking for, is that they’ve understood that writing tests makes their (future) life easier, too. A hobby project can benefit from that just as well. I’d argue almost even more so, because you might be working on a feature over the course of several weekends, where you’ll benefit from having written down the intended behavior at the start.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Tutorial: https://git-scm.com/book/en/v2/Git-on-the-Server-Setting-Up-the-Server